How I save tokens in Claude Code: Opus directs, Sonnet works
Last week I burned more tokens in one day than in the whole previous week combined.
It wasn't an experimental project. It was a crawler. A multi-site scraper running in Docker — 20 containers, each pulling data from a different site. Some were crashing, others returning nonsense, a few were hanging on timeouts. And I sat there in one long Claude Code chat with Opus, debugging logs one by one, fixing selectors, tweaking retry logic.
Opus for everything. Entire logs copied into context. One endless chat.
Then I looked at the usage and realized this couldn't go on. Not because Opus wasn't working — it was working great. But 80% of what I was asking it to do didn't need the most powerful model on the planet. It needed a smart system.
Here's that system.
Model hierarchy: who does what
The first thing I had to admit to myself: not every task needs the same brain.
Opus — the strategist
Opus is expensive. And that's exactly why you want to use it only where you truly need its abilities:
- Whole-system analysis — "look at the logs from 20 containers and tell me what's going on"
- Architectural decisions — "we have 5 sites with anti-bot protection, what's the best strategy?"
- Review and final check — "verify that these 3 fixes make sense together"
Opus excels where you need to hold a large context in your head and make complex decisions.
Sonnet — the workhorse
Sonnet is cheaper and perfectly sufficient for most concrete tasks:
- Fix a specific scraper based on an error log
- Update CSS selectors when a site's layout changes
- Write a new parser modeled on an existing one
- Debug a single container
Here's the key insight: Sonnet doesn't need to know the whole project. It just needs relevant context — a log, a script, a task. And that's exactly why it's so efficient.
Haiku — the runner
For simple, mechanical tasks:
- Formatting and cleaning data
- Generating boilerplate code
- Simple refactoring
- Grepping through logs and extracting relevant lines
In practice
A scraper for one eshop is crashing on HTTP 403. You don't need Opus to fix the header rotation — you send Sonnet the relevant log chunk and script, and it fixes it. You save Opus for the moment you need to redesign the entire scraping strategy for 5 sites at once.
In Claude Code it looks like this:
# Opus for strategy
claude --model opus "analyze errors across all scrapers and suggest a fix order"
# Sonnet for a specific fix
claude --model sonnet "here's the log from the eshop-alza container and the scraper script, fix the selector"
Agent delegation: Sonnet as your team
This is where it really starts paying off. Instead of one big Opus chat where you solve everything step by step, delegate specific tasks to subagents with a smaller model.
Picture it: 20 containers running. Three scrapers crashing. The old approach:
- Opus reads the first scraper's log (context grows)
- Opus fixes the first scraper (context grows)
- Opus reads the second scraper's log (context grows more)
- Opus fixes the second scraper (context is huge by now)
- ... and so on
Every subsequent fix is more expensive, because the model reads the entire previous context again and again.
New approach:
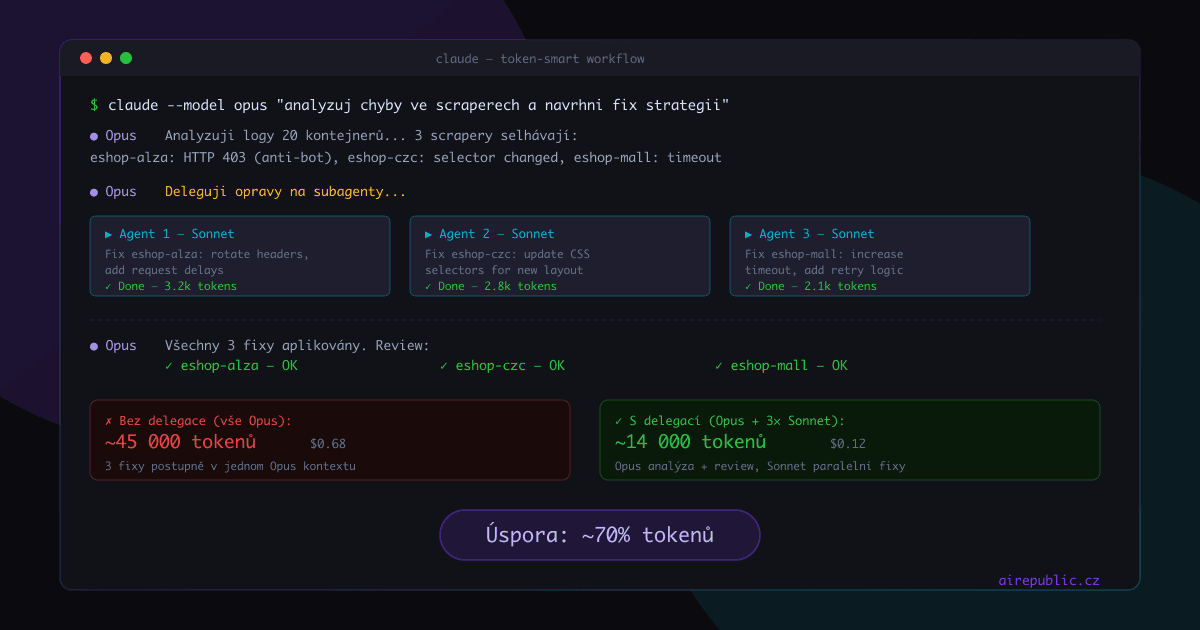
- Opus looks at an overview of errors and decides on a strategy
- For each fix, a subagent is spawned with Sonnet — it gets only what it needs
- Opus then reviews the results
The subagent gets a clean slate. No ballast from previous fixes, no old logs. Just: "here's the log, here's the script, fix it."
Key insight
The most expensive thing isn't the model, it's the context. When Opus holds the entire project in its head and you keep sending it more and more logs, you pay for every token in context with every next message. A subagent with a clean context and Sonnet is dramatically cheaper than Opus with a bloated context.
In practice, Opus might consume around 6,000 tokens for analysis and review, and three Sonnet subagents together another 8,000 on the actual fixes. Total ~14,000 tokens. If Opus did the same thing in one chat, you'd easily be at 45,000+.
Savings: ~70%.
And that's a conservative estimate — the more fixes in one chat, the more the context grows, and the more you pay for every subsequent message.
Context management: don't pay for air
You don't just pay tokens for answers. You mostly pay for context — for everything the model has to read before it answers you. The longer the conversation, the more expensive every subsequent message.
/compact — summarize and keep going
After a longer debugging session where you went through 5 logs and fixed 3 things, your context is full of old information. The /compact command condenses the conversation so far into a shorter summary. The model knows what happened, but doesn't have to read every line of a log you pasted in an hour ago.
I use it after every bigger fix. Fixed a scraper, confirmed it runs → /compact → next task.
/clear — clean start
When you move from fixing one scraper to an entirely different problem, there's no point in dragging old context along. /clear and you start with a clean chat. It's free and saves you tokens on every following message.
CLAUDE.md as permanent memory
This is crucial. Instead of explaining the project context at the start of every chat, you have CLAUDE.md in the repo root. Claude Code loads it automatically on startup.
In my scraper project I keep:
- The container structure and what each one does
- Conventions for writing scrapers (retry logic, error handling, output format)
- Common problems and their solutions
The model always sees it, I don't have to repeat it. And because it's loaded just once at the start, it's significantly more efficient than copy-pasting into every chat.
Targeted logs, not whole logs
This sounds trivial, but makes a huge difference. Instead of:
docker logs scraper-alza
...which dumps thousands of lines on you, send just the relevant bits:
docker logs scraper-alza 2>&1 | tail -50
docker logs scraper-alza 2>&1 | grep -i error | tail -20
50 lines instead of 5,000. The model doesn't need to see thousands of successful requests to understand one error. And you don't pay for air.
The system in a nutshell
| Situation | Model | Why |
|---|---|---|
| Whole-system analysis | Opus | Needs big context and complex judgment |
| Fix a specific scraper | Sonnet (subagent) | Relevant context is enough, 5× cheaper |
| Simple refactoring | Haiku | Mechanical work, doesn't need to think |
| After every fix | /compact | Shrinks context, saves on subsequent messages |
| New problem | /clear | Clean start, no ballast |
| Recurring context | CLAUDE.md | Write it once, always available |
Takeaways
I haven't stopped using Opus. Opus is great and nothing replaces it for strategic decisions. But I stopped wasting it on things Sonnet can handle at a fraction of the cost.
The whole trick is in how you think about working with AI. It's not one model, one chat, one context. It's a team — strategist, workhorses, and runners — each in its place.
And the 70% token savings? That's not theory. That's the real difference on my scraper project, where this workflow runs every day.
Next time we might look at setting up custom hooks that log your token usage automatically. But that's for another article.