Peak hours, moje chyba a 4 nástroje, co vrací tokeny
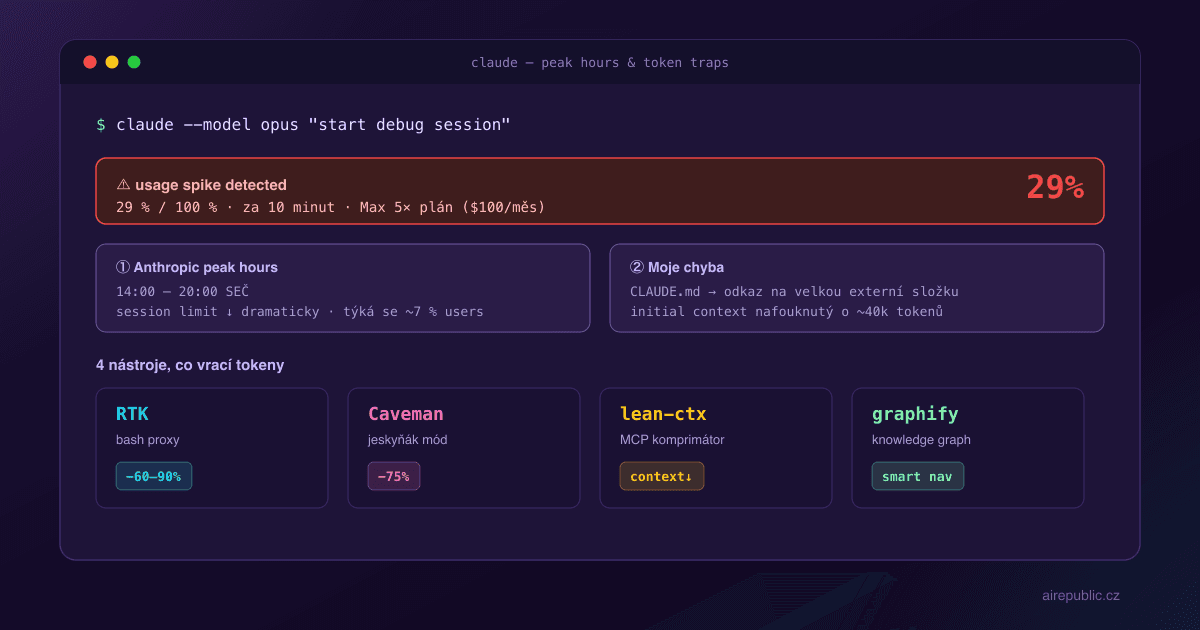
Začal jsem den normálně. Káva, editor, Claude Code, Max 5× plán za 100 dolarů měsíčně. Za pár minut práce se mi v hlavičce objevilo 29 % usage.
Dvacet devět procent. Za deset minut.
Napsal jsem frustrovaný post na Threads. Myslel jsem si, že to někdo lajkne, něco zamumlá a půjdeme dál. Místo toho se pod tím rozjela diskuze s desítkami reakcí z půlky světa — od Berlíňanů přes Kalifornii až po někoho z Bangalore, kdo měl úplně stejný problém.
A v průběhu té diskuze jsem si uvědomil dvě věci, které si typicky odporují, ale tady platí obě najednou: Anthropic má reálný problém. A zároveň jsem si půlku toho zavařil sám.
Co se skutečně děje s limity
V březnu 2026 Anthropic potichu zpřísnil session limity během peak hodin. Oficiální komunikace přišla až později, ale v podstatě to vypadá takhle:
- Týdenní limit zůstal stejný
- Session limity se ale během 14:00–20:00 SEČ vyčerpávají dramaticky rychleji
- Týká se to podle Anthropicu zhruba 7 % uživatelů — tedy ty, co jedou nejintenzivněji
Problém je, že když žiješ v Evropě a pracuješ přes den, spadáš do peak window prakticky celou pracovní dobu. 14:00 SEČ je 8 ráno na východním pobřeží USA — a v tu chvíli se infrastruktura začne promazávat americkým uživatelům a z našeho pohledu to vypadá, jako když ti někdo v reálném čase ukrajuje tokeny.
Není to iluze. Je to reálná změna v tom, jak se alokují compute resources. A není to úplně fér komunikované.
Ale.
Moje chyba (trapná, ale poučná)
Když jsem si v klidu prošel setup, narazil jsem na jednu řádku ve svém project CLAUDE.md. Byl v ní odkaz na velkou složku jiného projektu — něco, co jsem tam dal před týdny jako "referenci na inspiraci" a zapomněl.
Claude Code při každém startu session poctivě načítal celý ten cizí projekt. Tisíce řádků kódu, které s aktuální prací neměly nic společného.
Initial context je nejdražší část session. Platíš za něj každou další zprávu, protože model ho drží v hlavě celou dobu. Když tam máš 40k tokenů balastu, každá další otázka tě stojí o těch 40k víc.
Když jsem tu řádku smazal a session restartoval, první zpráva spotřebovala... normálně. Jak by se dalo čekat.
29 % za pár minut najednou dávalo smysl. Peak hour limit to zhoršoval, ale palivem byla moje vlastní chyba.
Čtyři nástroje, co reálně vrací tokeny
V té Threads diskuzi vypluly čtyři nástroje, které jsem neznal a od té doby na nich jedu. Ani jeden z nich nedělá zázraky sám — ale dohromady se úspora sčítá rychle.
RTK — Rust Token Killer
Transparentní proxy pro bash příkazy. Sedí mezi tebou a shellem, a všechno, co Claude Code spustí (git status, cat, grep, npm test…), nejdřív projede přes filtr, který ořízne balast — duplicitní řádky, verbose outputy, prázdné bloky.
brew install rtk && rtk init -g
V praxi to znamená −60 až −90 % na token usage u git/test/read operací. Projekt má přes 19 tisíc hvězd na GitHubu, takže není to ezoterika.
Caveman — jeskyňák mód
Skill, který přepíše systém prompt tak, že Claude odpovídá jako jeskyňák. Zní to jako vtip, ale technická přesnost zůstává plně zachovaná — jen zmizí zdvořilostní fráze, úvody, tři odstavce vysvětlování, proč je to dobrý nápad.
npx skills add JuliusBrussee/caveman
Měří se to na −75 % output tokenů. Místo „Great idea! Here's how I would approach this step by step..." dostaneš „Run npm install. Then edit line 42." Mně osobně to paradoxně zrychlilo i čtení odpovědí.
lean-ctx — kontextový komprimátor
MCP server + shell hook. Komprimuje veškerý kontext, který jde do modelu — před odesláním ho přežvýká, vyhodí redundance, sjednotí podobné pasáže.
curl -fsSL https://leanctx.com/install.sh | sh
Rozdíl poznáš hlavně v delších session, kde kontext organicky roste. Místo nabobtnaného chatu máš kontinuálně komprimovaný stav.
graphify — codebase jako graf
Asi nejzajímavější přístup z téhle čtveřice. Místo aby Claude četl raw soubory, si nejdřív postaví knowledge graph tvé codebase — komponenty, importy, závislosti, volání funkcí. Pak naviguje strukturou namísto sekvenčního čtení souborů.
pip install graphifyy
graphify install
graphify claude install
Hodí se hlavně u větších projektů, kde Claude jinak opakovaně čte stejné soubory dokola, aby si srovnal vztahy.
Best practices z diskuze
Kromě nástrojů padlo v té diskuzi i pár návyků, které stojí za zmínku. Některé jsem rozebíral už v předchozím článku o šetření tokenů, takže tady jen bodově:
- Sonnet na agenty, Opus jen na strategii — Opus je na iniciální analýzu a review, ale 80 % konkrétní práce zvládne Sonnet levněji
/compactpo každé větší změně — shrne dosavadní kontext, další zprávy platíš z menšího základu- Nová konverzace pro každý nový task — žádné tahání balastu mezi nesouvisejícími úkoly
- Krátké, stručné CLAUDE.md — bez odkazů na velké externí složky (viz výše, moje chyba)
- Žádné velké externí reference v project instrukcích — pokud potřebuješ něco ukázat, pošli to ad-hoc do konkrétní zprávy
- Náročnější práci mimo peak hodiny — před 14:00 nebo po 20:00 SEČ to chodí jinak
/contextpro sledování aktuálního stavu — přestaneš hádat a uvidíš, kolik toho model vlastně drží
Co si z toho odnést
Threads post jsem psal ve frustraci a čekal solidární lajky. Místo toho mi diskuze ukázala, že realita je skoro vždycky „a" místo „nebo".
Anthropic skutečně zpřísnil peak hour limity a komunikoval to mizerně. To je legitimní stížnost.
Zároveň jsem měl v project instrukcích bomba, která mi první zprávu nafukovala o desítky tisíc tokenů. To je moje chyba.
Obojí platí. A v praxi to znamená, že i když nemůžeme ovlivnit, jak Anthropic rozděluje compute během špičky, máme docela velký vliv na to, kolik tokenů doopravdy spotřebujeme. RTK, Caveman, lean-ctx, graphify plus pár návyků — a ze stejné práce najednou zbude víc limitu na konec týdne.
Drahá lekce. Ale asi nejvíc se mi za 100 dolarů měsíčně vyplatila právě tahle.